
Saya mengadaptasi gambaran berikut dari Chris Sherman dan gambaran indah Gary Price tentang Cara Kerja Search Engine dalam Bab 2 The Web Invisible (Buku CyberAge, 2001).
Google berjalan pada jaringan terdistribusi dari ribuan komputer murah dan karena itu dapat melaksanakan pemrosesan paralel cepat. Pengolahan paralel adalah metode perhitungan di mana banyak perhitungan dapat dilakukan secara bersamaan, secara signifikan mempercepat pengolahan data. Google memiliki tiga bagian yang berbeda:
* Googlebot, web crawler yang menemukan dan mengambil halaman web.
* Para pengindeks yang macam setiap kata pada setiap halaman dan menyimpan indeks yang dihasilkan kata dalam database besar.
* Prosesor query, yang membandingkan permintaan pencarian Anda ke indeks dan merekomendasikan dokumen yang dianggap paling relevan.
Mari kita melihat lebih dekat pada setiap bagian.
1. Googlebot, Google’s Web Crawler
Googlebot is Google’s web crawling robot, yang menemukan dan mengambil halaman di web dan menyerahkan mereka ke indexer Google. Sangat mudah untuk membayangkan Googlebot sebagai laba-laba kecil berlarian di helai dunia maya, namun pada kenyataannya Googlebot tidak melintasi web sama sekali. Berfungsi seperti browser web Anda, dengan mengirimkan permintaan ke web server untuk halaman Web, men-download seluruh halaman, kemudian menyerahkannya ke indexer Google.
Googlebot terdiri dari banyak komputer meminta dan mengambil halaman jauh lebih cepat dari yang Anda dapat dengan browser web Anda. Bahkan, Googlebot dapat meminta ribuan halaman yang berbeda secara bersamaan. Untuk menghindari server web yang luar biasa, atau permintaan crowding out dari pengguna manusia, Googlebot sengaja membuat permintaan dari masing-masing web server individu lebih lambat dari itu mampu melakukan.
Googlebot menemukan halaman dalam dua cara: melalui formulir add URL, www.google.com / addurl.html, dan melalui menemukan link dengan merangkak web.
Sayangnya, spammer menemukan cara untuk membuat bot otomatis yang dibombardir bentuk URL add dengan jutaan URL yang menunjuk ke propaganda komersial. Google menolak semua URL yang dikirimkan melalui form Add URL nya bahwa tersangka berusaha untuk menipu pengguna dengan menggunakan taktik seperti termasuk teks tersembunyi atau link pada halaman, isian halaman dengan kata-kata yang tidak relevan, cloaking (umpan alias dan switch), menggunakan sneaky redirects , menciptakan pintu, domain, atau sub-domain dengan konten hakekatnya sama, mengirimkan query otomatis ke Google, dan terhubung ke tetangga yang buruk. Jadi sekarang Tambahkan URL bentuk juga memiliki tes: ini akan menampilkan beberapa berlekuk-lekuk huruf yang dirancang untuk menipu otomatis "surat-menebak"; meminta Anda untuk memasukkan huruf yang Anda lihat - sesuatu seperti tes mata-chart untuk menghentikan robot spam.Ketika Googlebot menjemput halaman, itu sisa-sisa semua link muncul pada halaman dan menambahkan mereka ke antrian untuk merangkak berikutnya. Googlebot cenderung menghadapi spam yang sedikit karena penulis web yang paling link hanya untuk apa yang mereka yakini berkualitas tinggi halaman. Dengan panen link dari setiap halaman itu pertemuan, Googlebot dapat dengan cepat membangun sebuah daftar link yang dapat mencakup jangkauan yang luas dari web. Teknik ini, dikenal sebagai merangkak dalam, juga memungkinkan Googlebot untuk menyelidiki jauh di dalam setiap situs. Karena skala besar mereka, dalam merangkak dapat mencapai hampir setiap halaman di web. Karena web sangat luas, hal ini dapat memakan waktu, sehingga beberapa halaman mungkin dijelajahi hanya sekali sebulan.Meskipun fungsinya sederhana, Googlebot harus diprogram untuk menangani beberapa tantangan. Pertama, sejak Googlebot mengirimkan permintaan secara simultan untuk ribuan halaman, antrian URL "kunjungi segera" harus selalu diperiksa dan dibandingkan dengan URL sudah di indeks Google. Duplikat dalam antrian harus dihilangkan untuk mencegah Googlebot dari mengambil halaman yang sama lagi. Googlebot harus menentukan seberapa sering untuk mengunjungi kembali halaman. Di satu sisi, ini adalah pemborosan sumber daya untuk kembali indeks halaman tidak berubah. Di sisi lain, Google ingin kembali berubah halaman indeks untuk memberikan up-to-date hasil.Untuk menjaga arus indeks, Google terus recrawls populer sering mengubah halaman web pada tingkat kasar sebanding dengan seberapa sering perubahan halaman. Seperti merangkak menjaga indeks saat ini dan dikenal sebagai segar merangkak. Halaman koran-download harian, halaman dengan harga saham di-download lebih sering. Tentu saja, segar kembali menjelajah halaman lebih sedikit daripada merangkak dalam. Kombinasi dari dua jenis merangkak memungkinkan Google untuk kedua memanfaatkan sumber daya yang efisien dan menjaga indeksnya cukup saat ini.
2. Google’s Indexer
Googlebot memberikan pengindeks teks lengkap dari halaman yang ditemukan. Halaman-halaman ini disimpan dalam database indeks Google. Indeks ini diurutkan menurut abjad berdasarkan istilah pencarian, dengan setiap entri indeks menyimpan daftar dokumen di mana istilah itu muncul dan lokasi dalam teks mana itu terjadi. Struktur data ini memungkinkan akses cepat ke dokumen yang berisi istilah permintaan pengguna.
Untuk meningkatkan performa pencarian, Google mengabaikan (tidak indeks) umum kata atau kata-kata henti (seperti, adalah, pada, atau, dari, bagaimana, mengapa, serta digit-digit dan huruf tunggal). Hentikan kata-kata sangat umum bahwa mereka berbuat banyak untuk mempersempit pencarian, dan karena itu mereka dapat dengan aman dibuang. Indexer juga mengabaikan beberapa tanda baca dan beberapa ruang, serta mengkonversi semua huruf menjadi huruf kecil, untuk meningkatkan kinerja Google.
3. Google’s Query Processor
Prosesor query memiliki beberapa bagian, termasuk user interface (kotak pencarian), "mesin" yang mengevaluasi permintaan dan sesuai dengan mereka untuk dokumen yang relevan, dan formatter hasil.
PageRank adalah sistem Google untuk halaman web peringkat. Sebuah halaman dengan PageRank yang lebih tinggi dianggap lebih penting dan lebih mungkin untuk dicatatkan atas halaman dengan PageRank rendah.
Google menganggap lebih dari seratus faktor dalam komputasi PageRank dan menentukan dokumen mana yang paling relevan dengan query, termasuk popularitas halaman, posisi dan ukuran istilah pencarian di dalam halaman, dan kedekatan istilah pencarian satu sama lain pada halaman. Sebuah aplikasi paten membahas faktor-faktor lain yang Google menganggap ketika peringkat halaman. Kunjungi laporan SEOmoz.org karena interpretasi konsep dan aplikasi praktis yang terdapat dalam aplikasi paten Google.
Google juga berlaku mesin-belajar teknik untuk meningkatkan kinerjanya secara otomatis dengan mempelajari hubungan dan asosiasi di dalam data yang tersimpan. Sebagai contoh, sistem ejaan-koreksi menggunakan teknik tersebut untuk mengetahui ejaan alternatif mungkin. Google erat penjaga menggunakan rumus untuk menghitung relevansi; mereka tweak untuk meningkatkan kualitas dan kinerja, dan mengecoh teknik licik terbaru yang digunakan oleh spammer.
Pengindeksan teks lengkap dari web memungkinkan Google melampaui hanya pencocokan istilah pencarian tunggal. Google memberikan prioritas untuk halaman yang memiliki istilah pencarian dekat satu sama lain dan dalam urutan yang sama seperti query. Google juga dapat mencocokkan multi-kata frase dan kalimat. Karena kode HTML Google indeks selain teks pada halaman, pengguna dapat membatasi pencarian berdasarkan kata-kata di mana permintaan muncul, misalnya, dalam judul, di URL, di dalam tubuh, dan di link ke halaman, opsi yang ditawarkan dengan Formulir Pencarian Lanjutan Google dan Menggunakan Operator Pencarian (Operator Advanced).
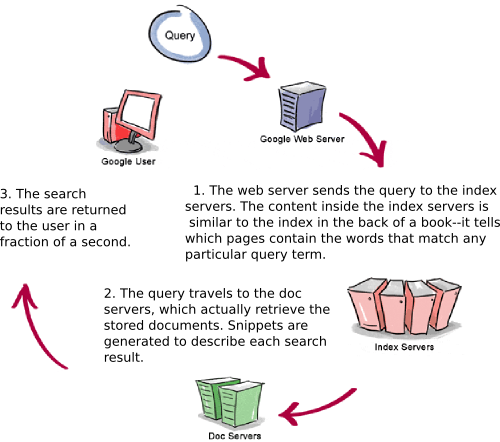
Mari kita lihat bagaimana Google memproses query.
Terkait
Description:
bagaimana google bekerja
Rating:
4.5
Reviewer:
Evanzz Cyber4rt
ItemReviewed:
bagaimana google bekerja
Al
Mbah Qopet Updated at:
02.18



0 komentar:
Posting Komentar
Berkomentarlah Dengan Sopan!!!